IVCR-200K: A Large-Scale Multi-turn Dialogue Benchmark for Interactive Video Corpus Retrieval


Abstract
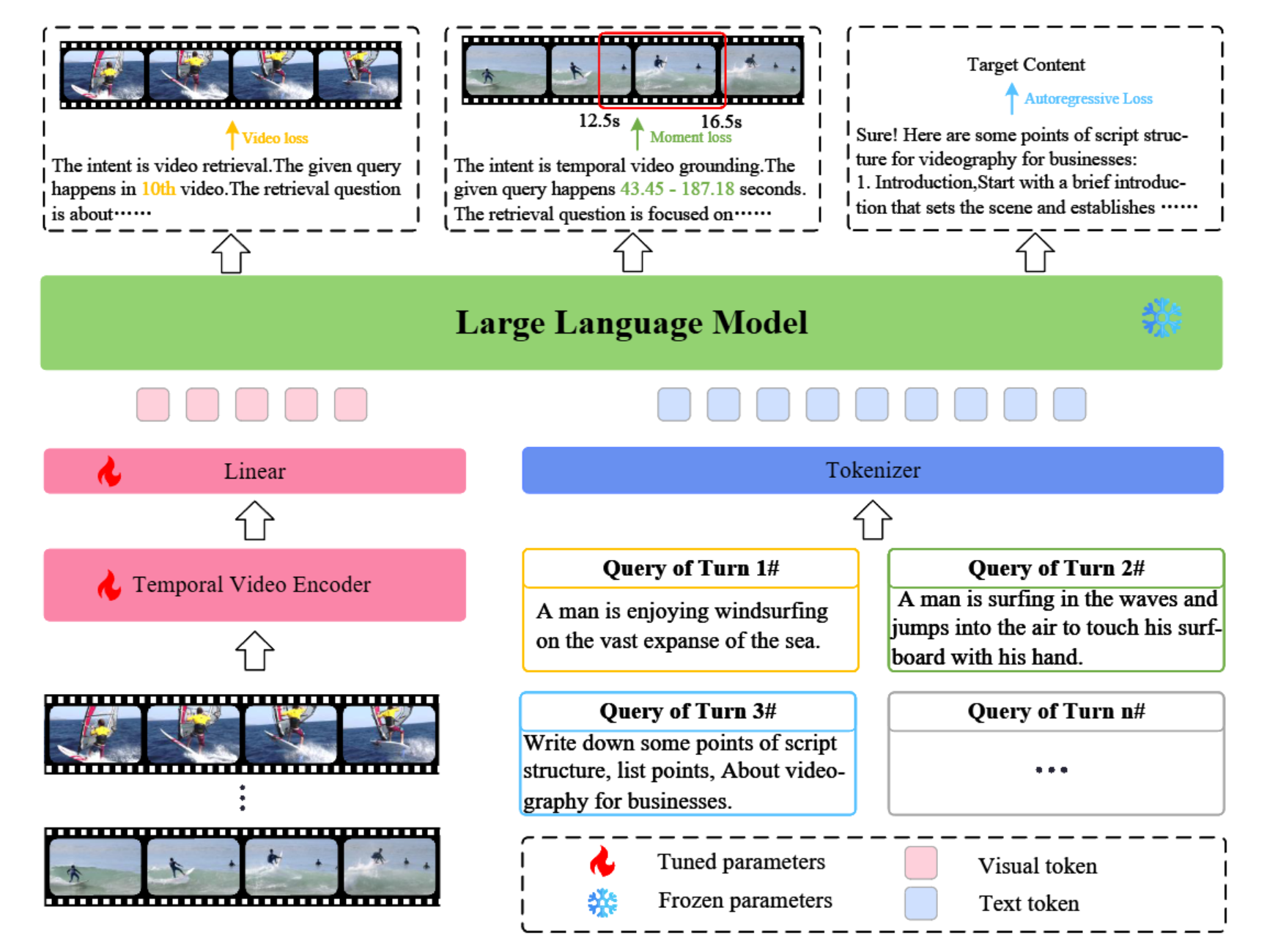
In recent years, significant developments have been made in both video retrieval and video moment retrieval tasks, which respectively retrieve complete videos or moments for a given text query. These advancements have greatly improved user satisfaction during the search process. However, previous work has failed to establish meaningful “interaction” between the retrieval system and the user, and its one-way retrieval paradigm can no longer fully meet the personalization and dynamics of user needs. In this paper, we propose a more realistic setting, Interactive Video Corpus Re- trieval task (IVCR) that enables multi-turn, conversational, realistic interactions between the user and the retrieval system. To facilitate research on this challenging task, we introduce IVCR-200K, a bilingual, multi-turn, conversational, abstract se- mantic high-quality dataset that supports video retrieval and even moment retrieval. Furthermore, we propose a comprehensive framework based on multi-modal large language models (MLLMs) to support users’ several interaction modes with more explainable solutions. Our extensive experiments demonstrate the effectiveness of our dataset and framework.
Datasets
To implement an interactive video retrieval system, we constructed a multi-turn, conversational dataset comprising 193,434 interactions sourced from 5 video repositories. This dataset encompasses functionalities such as video retrieval, video moment retrieval, and natural dialogue.




Visualization Quality

Framwork